
What We're Testing Here
There's a new(ish) kid on the robots directive block, indexifembedded. Currently only supported by
Google, the aim is to allow content to be indexed as part of the page it's embedded on, but not on its own. To
achieve
that it needs to be paired with a noindex too.
You can get more in-depth detail about what indexifembedded is meant to do from Google's blog post: New robots tag: indexifembedded.
I'd given it a cursory test, but didn't think much more about it but this Twitter thread from @jakebohall and @RichTatum:

prompts some interesting questions, does it REALLY work the way we expect it? Does it work with PDFs?
Setting Up the Test
I created a very simplistic site in a subfolder of my testing domain here: https://testing.tamethebots.com/indexifembedded/, a basic index page, then 6 other pages each containing a different variation of robots directives, for html content and pdf content.
They are:
- A page with an iframe with html embed containing noindex & indexifembedded
- A page with an iframe with html embed containing just noindex
- A page with an iframe with html embed, no robots meta
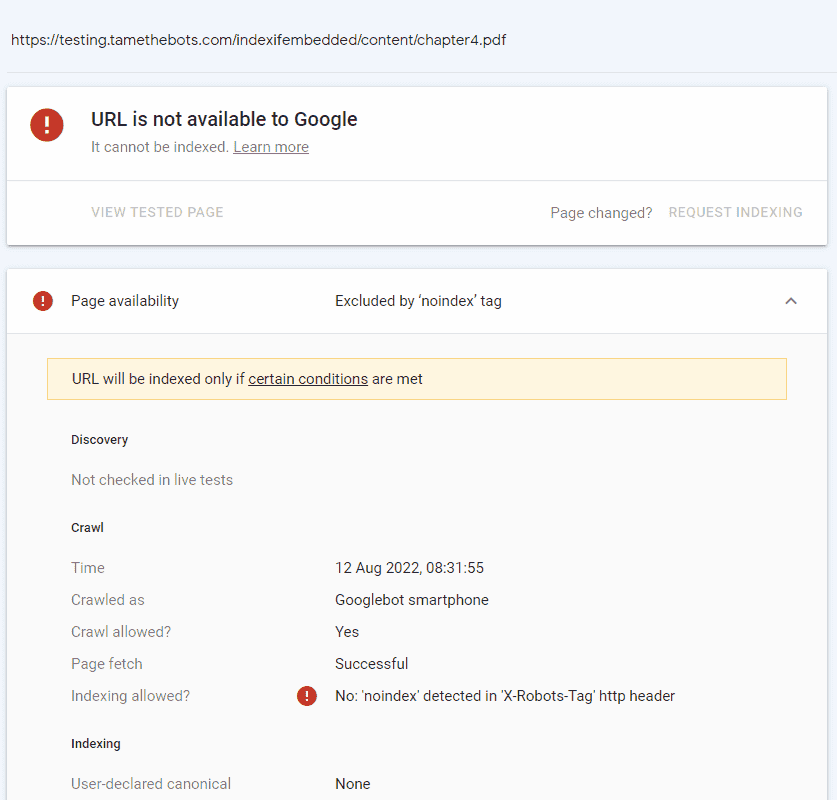
- A page with an iframe with pdf, the pdf has an X-Robots-Tag: googlebot: noindex, indexifembedded HTTP header
- A page with an iframe with pdf, the pdf has an X-Robots-Tag: googlebot: noindex HTTP header
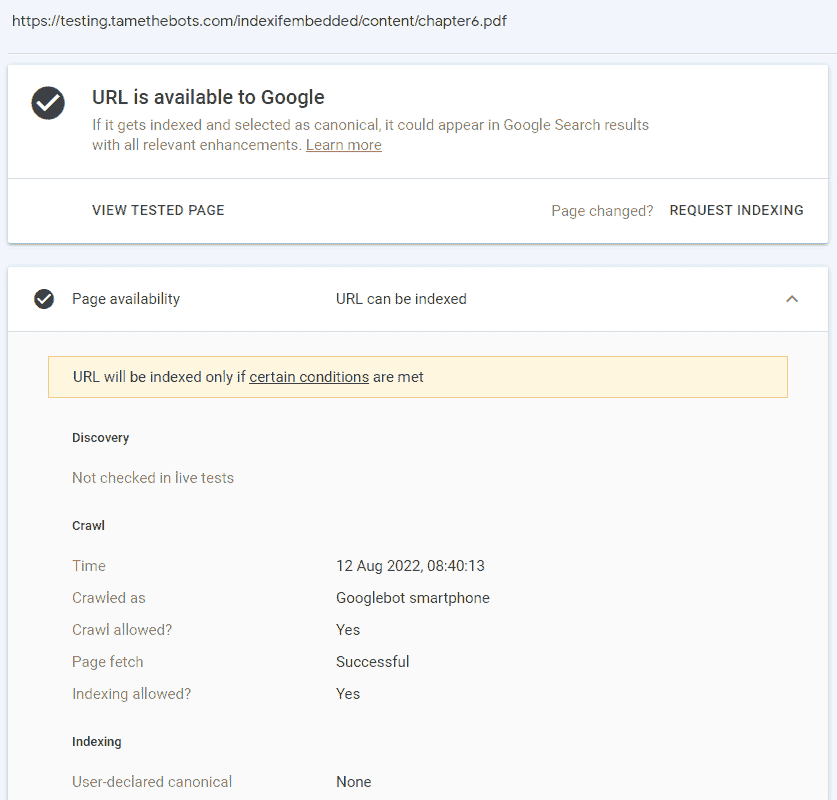
- A page with an iframe with pdf, the pdf has no X-Robots-Tag HTTP header
Each of the pages has the first paragraph of a story (if any publishers want to get in touch for a children's book series, I'm available …), with the rest in the embed.
I added the URLs to a sitemap and waited for indexing.
The Outcomes
I monitored search console for each test page, and each embed's Page indexing status, and also used the URL Inspection tool to check each page, both the indexed content and a live test.
Of note is that for all pages, including the pdf ones, the embed file was listed as successfully fetched under the More Info > Page Resources list. Something backed up by checking server logs.
Test 1. HTML content, noindex & indexifembedded
See: The Test Page | The Embedded File
Search Console Status
Test Page: Submitted and Indexed
Embedded File: Submitted URL marked ‘noindex’
URL Inspector - Crawled HTML
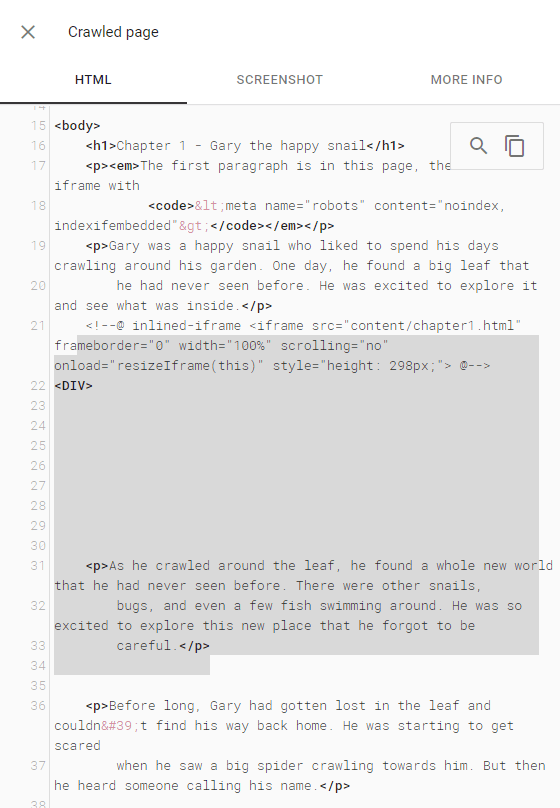
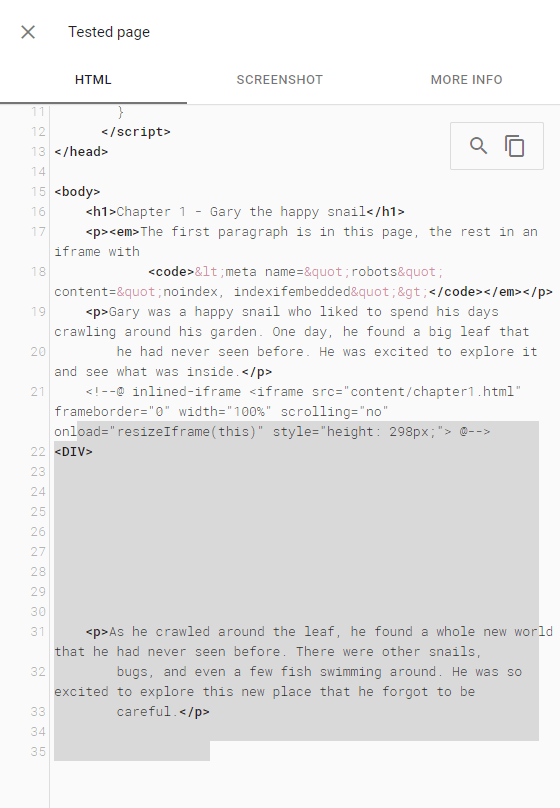
URL Inspector - Live Test HTML
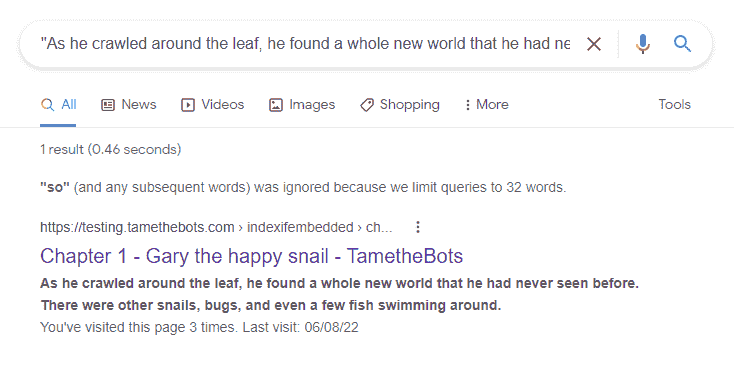
Search Results
Verdict - Works as expected
The test page shows up for content from the embedded file in search, but the embedded file is not indexed.
Test 2. HTML content, noindex
See: The Test Page | The Embedded File
Search Console Status
Test Page: Submitted and Indexed
Embedded File: Submitted URL marked ‘noindex’
URL Inspector - Crawled HTML
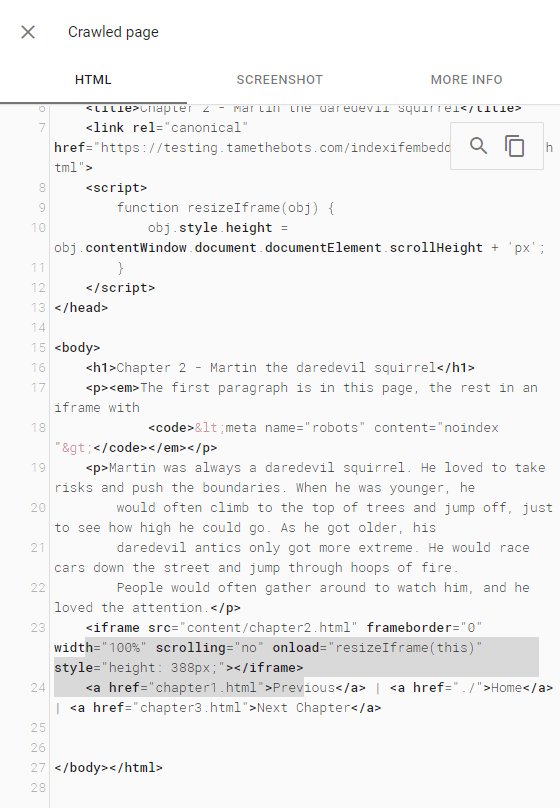
URL Inspector - Live Test HTML
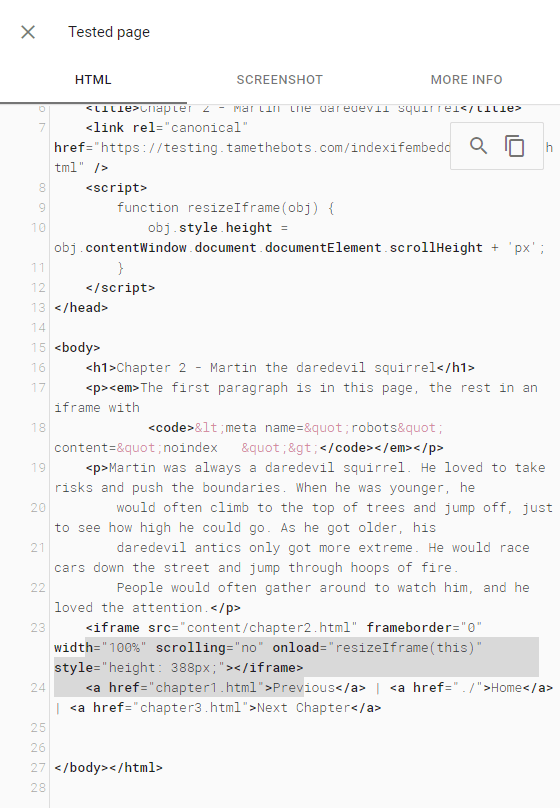
Search Results
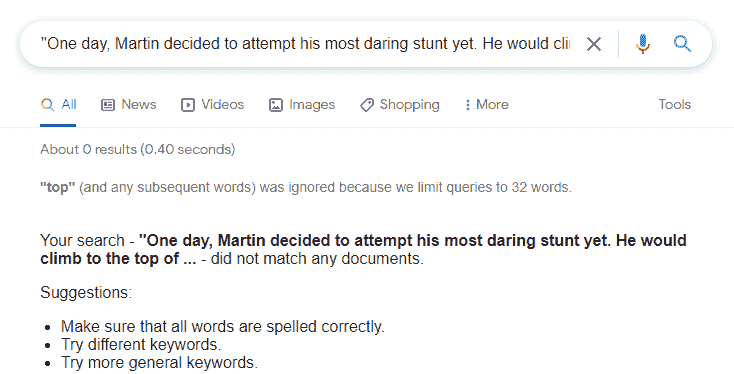
Verdict - Works as expected
The test page doesn't return in search for content from the embedded file in search, and the embedded file is not indexed. The page did return for a search for text from the first paragraph, which is on the test page.
Test 3. HTML content without robots directives
See: The Test Page | The Embedded File
Search Console Status
Test Page: Submitted and Indexed
Embedded File: Submitted and Indexed
URL Inspector - Crawled HTML
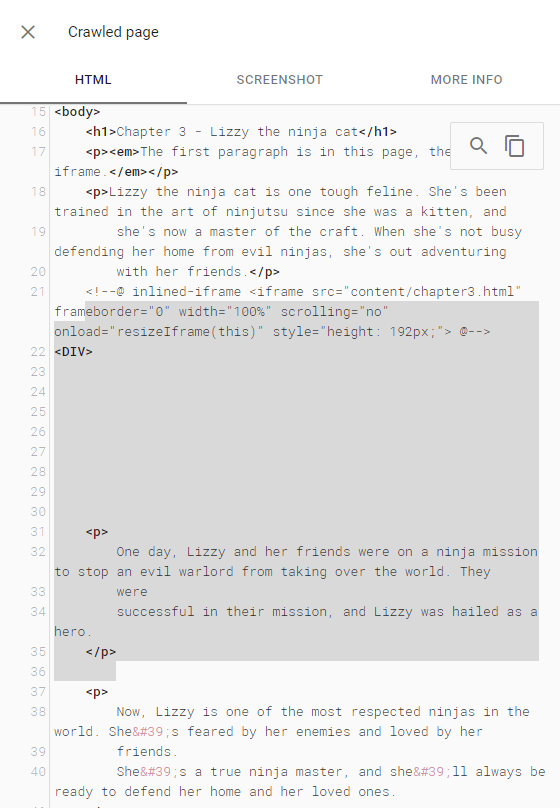
URL Inspector - Live Test HTML

Search Results
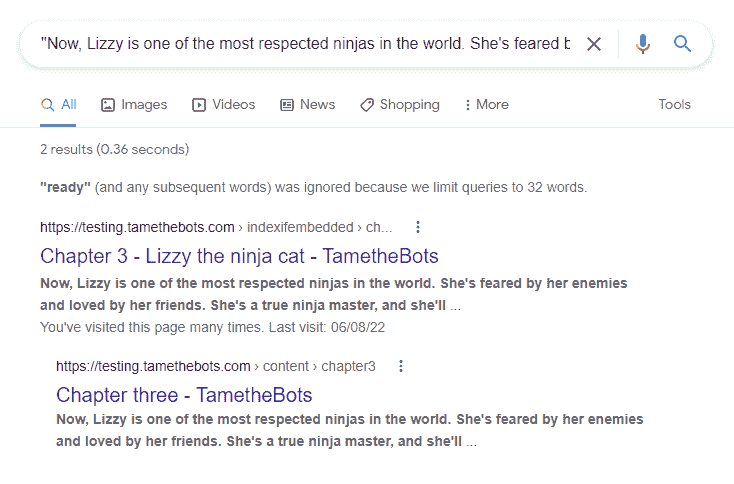
Verdict - Works as expected
Both the test page and the html page that's embedded ended up indexed and returning for an exact match search for content from the embedded file.
Test 4. PDF content with X-Robots-Tag: googlebot: noindex, indexifembedded
See: The Test Page | The Embedded File
Search Console Status
Test Page: Submitted and Indexed
Embedded File: Submitted URL marked ‘noindex’
URL Inspector - Crawled HTML
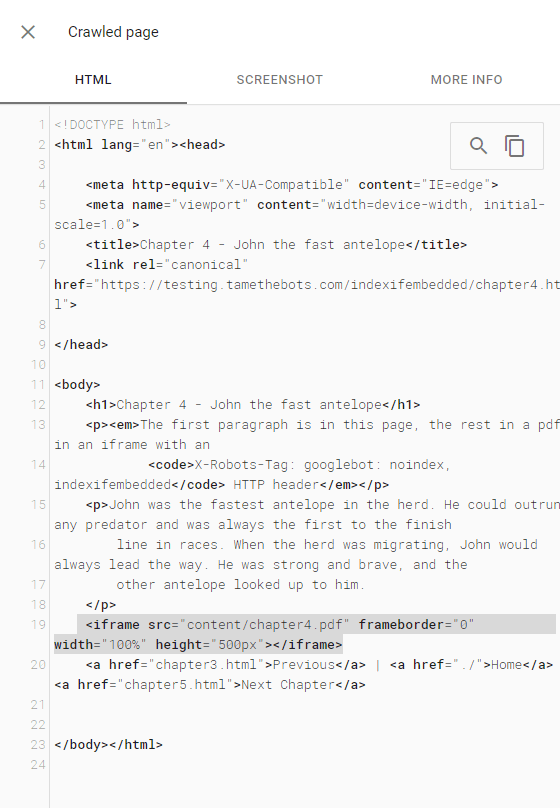
URL Inspector - Live Test HTML
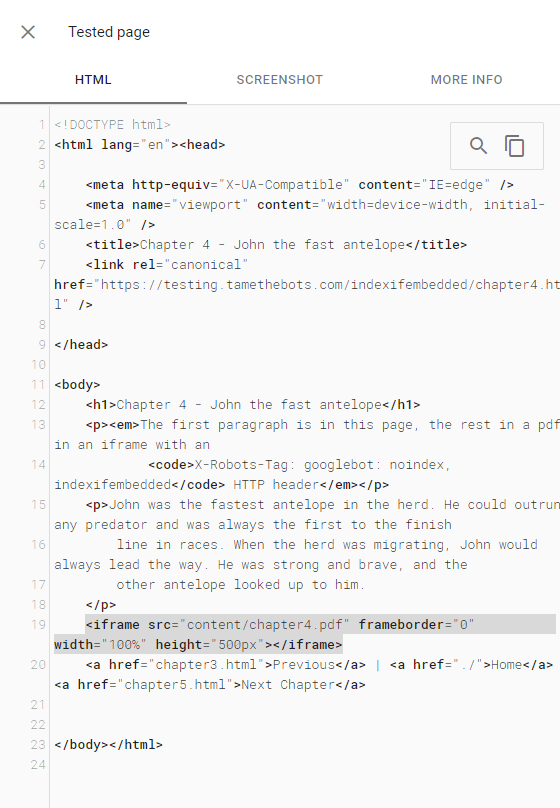
Search Results
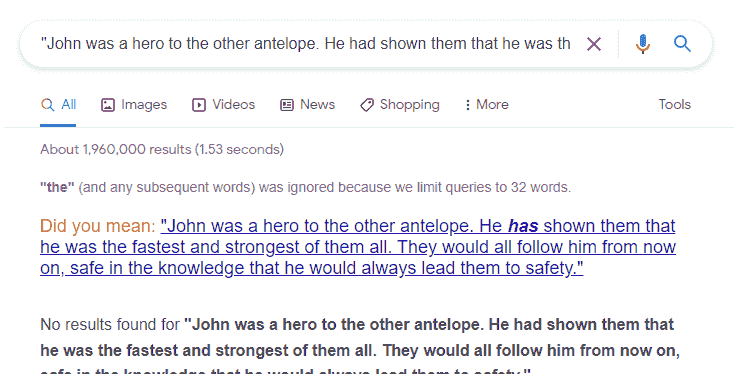
Verdict - Sort of expected
The PDF didn't get indexed as part of the page, and the PDF didn't end up indexed or returned in a search. The page did return for a search for text from the first paragraph, which is on the test page.
Test 5. PDF content with X-Robots-Tag: googlebot: noindex
See: The Test Page | The Embedded File
Search Console Status
Test Page: Submitted and Indexed
Embedded File: Submitted URL marked ‘noindex’
URL Inspector - Crawled HTML
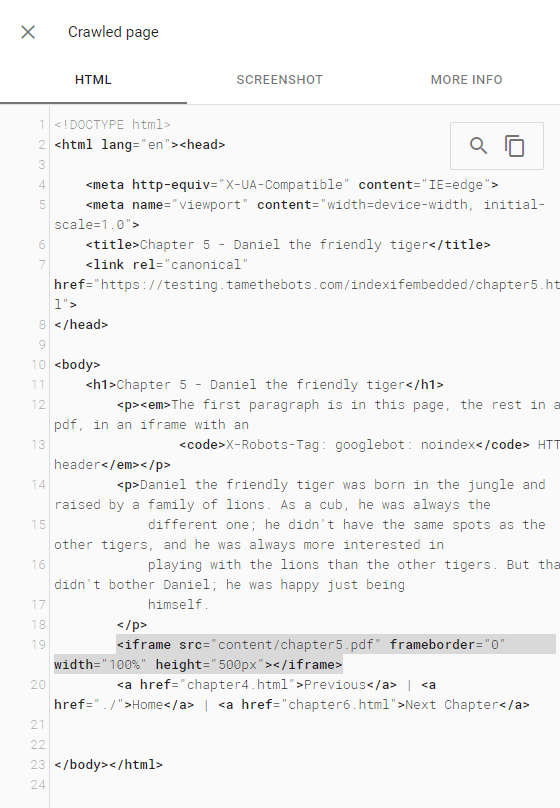
URL Inspector - Live Test HTML
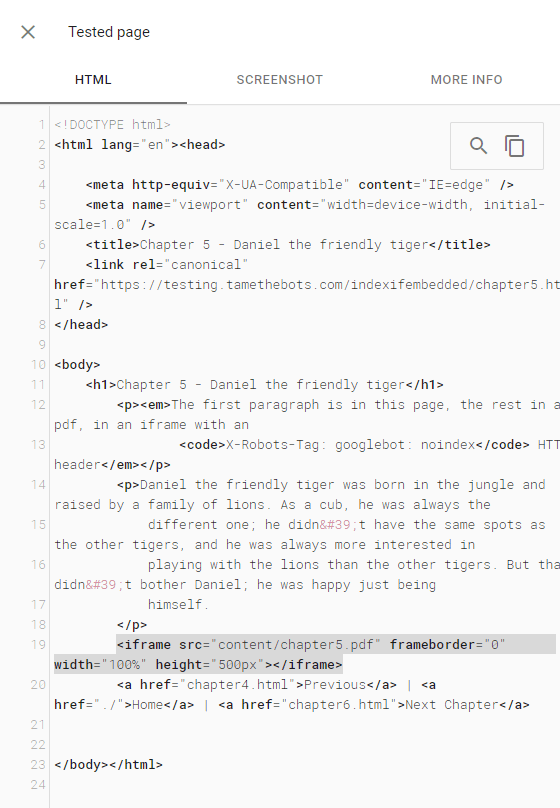
Search Results
Verdict - Works as expected
The PDF didn't get indexed as part of the page, and the PDF didn't end up indexed or returned in a search. The page did return for a search for text from the first paragraph, which is on the test page.
Test 6. PDF content with no X-Robots-Tag header
See: The Test Page | The Embedded File
Search Console Status
Test Page: Submitted and Indexed
Embedded File: Submitted and indexed
URL Inspector - Crawled HTML
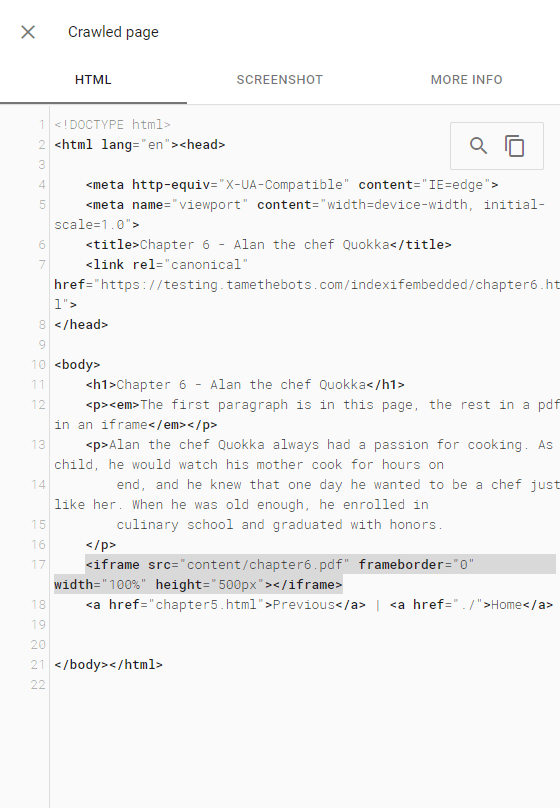
URL Inspector - Live Test HTML

Search Results
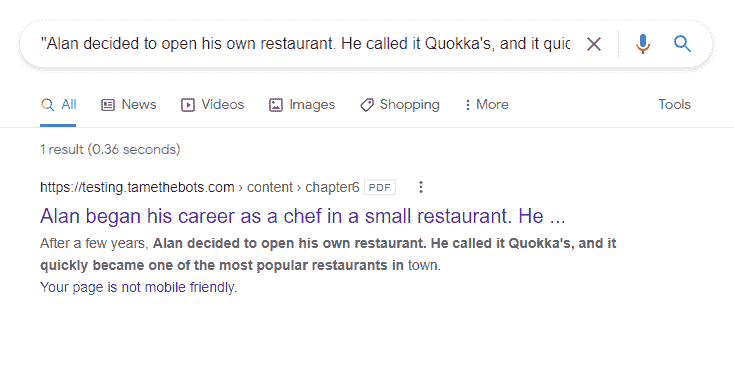
Verdict - Sort of expected
The PDF didn't get indexed as part of the page, but the PDF did get indexed and returned in a search for content it contained. The page did return for a search for text from the first paragraph, which is on the test page.
Conclusions
The new tag works as I would expect, and of note, it enables what test 1 covers, being able to have something indexed as part of a page, but no risk of it surfacing independently, like in test 3.
In the past, there wasn't a real way to achieve that, canonical tags on the content being embedded could perhaps point to a search engine what you are wanting to achieve, but the embed is only ever part of the content, not the whole content. I can see a lot of times this might have been ignored. Suggestion versus directive.
Naturally, the tests are a very simplistic use case, but I can see the usefulness of the tag in other situations.
Perhaps something like a Jobs board offering an iframe widget with a company's vacancies for them to add to their pages, or even simplify things like the Disqus comments I use on this site.
Another thing the tests show is that PDF content isn't flattened into the main document anyway, which was something I wasn't 100% sure what the behaviour was there anyway, hence the 'Sort of expected' verdict. But it seems they're never flattened into the main document and adding the indexifembedded tag doesn't change that, a test Jake Bohall focused on more in their indexifembedded testing. Whilst ultimately we ended up roughly the same, we did get different results for the PDF with noindex, indexifembedded, Jake's ended up indexed, which I certainly wouldn't expect, mine didn't. I suspect that Google isn't seeing the noindex for some reason.
Are the testing tools Google provides sufficient?
I would say yes, but with a caveat. The URL inspection tool matched what would be flattened into the main document and what wouldn't.
I would say that checking PDF statuses are harder than it should be. Or at least it's more limited. For a page, it's possible for anyone to check if a page could be indexed in in something like the mobile-friendly tool, or the rich-result test. But these are limited to web pages, so checking a PDF leads to a rather unhelpful "Something Went Wrong". So you can only check with the URL inspector live test. The rendered HTML in a live test will make no sense, but you can see responses through the more info tab.
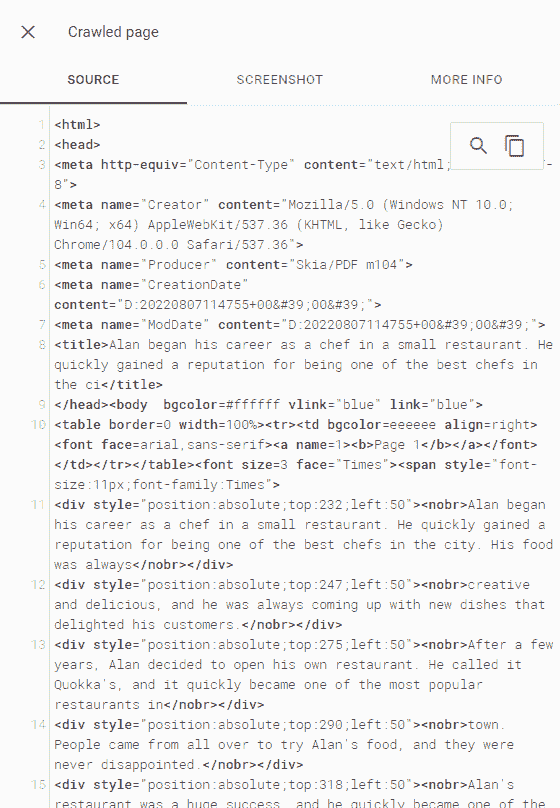
For PDFs that are indexed, if you look at the rendered HTML in the initial (not live) URL inspector test, you can see the HTML representation Google create from your PDFs to enable them to be indexed and shown in web search.
TL;DR
indexifembedded works as advertised for html content but has no effect on PDFs embedded, as these aren't
flattened into the main document anyway.