
Hold on, a Web What?
I'm not planning a deep dive into what web workers are here, so a quick overview is:
- Executing JavaScript blocks the main thread.
- If the main thread is blocked the browser can't do anything.
- Web Workers let you get around this by offloading long-running tasks to a different thread, leaving the main thread free
If you want to learn a bit more, perhaps start here: Using Web Workers on MDN Web Docs or Workers overview - web.dev.
Note: Web Workers are not the same thing as service workers, this is about web workers only.
The Test
A client approached me, they had a plan to calculate some data client-side. It was a large table of data, that required some columns to be calculated and it was on the heavy side, it could block the main thread, therefore the browser, for multiple seconds.
So fairly rationally, they thought Web Workers might be the way forward. However, they also wanted this data to be indexable. So for that reason, it was time to get testing.
The Subject.
I already knew Google could execute Web Workers successfully, I had built a test page and tried it out, but it was very, very simplistic. I'm a big fan of Using minimal, reproducible examples, it helps you focus on just this issue, but you still need to cover enough of the different variables.
So I reworked the test page, which you can find here: https://testing.tamethebots.com/webworker.html.
This test page calls 4 different web workers
- Worker 1:
Returns the timestamps of when the worker was called and when it responded (this happens in almost an instant), this is then displayed on the page. - Worker 2:
The worker uses the fetch API to request a simple endpoint to get a timestamp and then returns that and displays it. - Worker 3:
Does the same thing as 2, but using XMLHttpRequest instead of fetch. - Worker 4:
This worker contains a long-running calculation, to simulate something similar to what might happen in this clients case. This returns timestamps when the worker was called, and when it responded (like worker 1)
Testing What Gets Rendered.
I then ran this test page through the URL Inspection Tool to see what Google would see. I ran the test a few times to check that it wasn't resources not being fetched (there are the 4 worker files, and 2 API calls here). Finally, I requested indexing to see what ultimately would get indexed and if that matched the tests.
The Results
Here's the output from the URL Inspection tool (I copied the rendered HTML, and popped that in an HTML file, minus the JavaScript, to create a full screenshot),
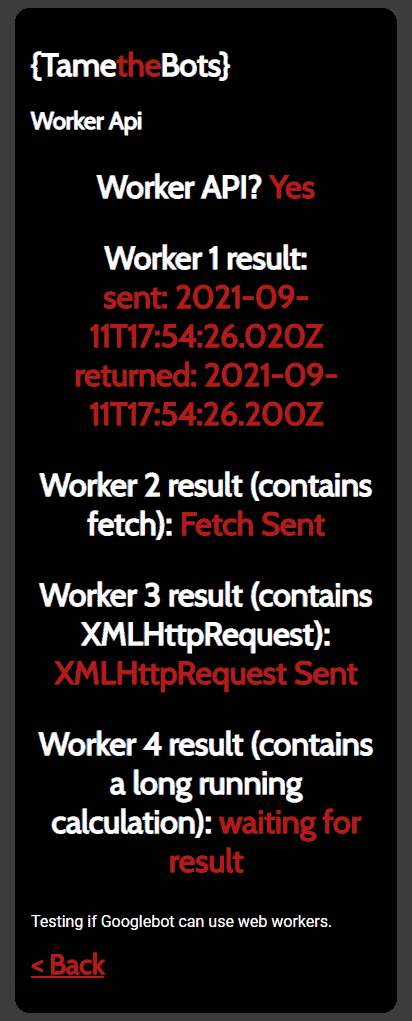
Worker 1 - OK
From prior tests, with just worker 1, I knew Google could render that test just fine, and that stayed the case.
Workers 2 & 3 - Fail
It turns out that if the worker contained a fetch, or XMLHttpRequest (workers 2 & 3) Googlebot cannot render this, and the XHR call is always reported as other error.

Checking log files shows that Googlebot did request this file each time, just not using it.
Worker 4 - It Depends.
This one is interesting, as I had it set up (and as it is now), it failed, however, if I reduced how long the script took to run, it reliably worked if the worker returned the results in under 1 second. Over one second, it reliably failed.
Does the Actual Indexing Process Match?
The results once the page was indexed matched the behaviour of the live test.
Conclusions
Whilst Google can, in some circumstances, execute web workers in their Web Rendering Service, there are limitations.
In the context of what web workers are useful for, these limitations mean that for all practical purposes, content that relies on web workers is not going to get indexed.
Fetching additional data from the web worker could potentially be avoided, you could do the call directly in the page, then pass that data to the worker.
The 1-second limitation isn't really possible to workaround. It's probably a long-running task, that's why you are shifting it off the main thread in the first place. It would be hard to guarantee how long a task would run for anyway. It would be running in Google's WRS, and that's outside of your control, and we have no way of really knowing how much CPU etc. this has, and if it consistently has the same level of resources.
Therefore my advice to the client, and you, is to avoid web workers providing content you want to be indexed.